Дата создания: 22 ноября 2022
Обновлено: 29 декабря 2023
Математика нестарения. Часть -3. Сколько человек должно участвовать в эксперименте

Многие клинические исследования, которые мы читаем, не представляют доказательств эффективности лекарства потому, что в таких экспериментах слишком маленький размер выборки - мало участников эксперимента. В контексте клинических исследований выборка - это то количество людей, которые участвуют в эксперименте.
Почему важно понимать, какой нужен размер выборки. Например, в последние годы в моду вошли так называемые будто «улучшатели» умственных способностей. Адепты ссылаются на эксперименты, в которых проверяли их эффективность. Давайте посмотрим, какие самые большие выборки были в удачных экспериментах таких «улучшателей» умственных способностей.
- Амфетамин, который регулируется, как наркотическое средство и запрещен в РФ. Выборка около в экспериментах - 20-30 человек в группе [pubmed.ncbi.nlm.nih.gov/24749160].
- Модафинил, который регулируется, как наркотическое средство и запрещен в РФ. Например, 37 человек в группе [pubmed.ncbi.nlm.nih.gov/3143333].
- Метилфенидат, который регулируется, как наркотическое средство и запрещен в РФ. Эксперименты, опубликованные до 2005 года, не имели по факту проспективного дизайна. А единственный эксперимент, опубликованный после 2005 года, имел выборку ~ 20 человек [pubmed.ncbi.nlm.nih.gov/25591060].
- ЛевоДопа. Выборка 36 человек в обеих группах в сумме [pubmed.ncbi.nlm.nih.gov/23661634], 40 человек в обеих группах [pubmed.ncbi.nlm.nih.gov/18312589], 18 человек в обеих группах в сумме [pubmed.ncbi.nlm.nih.gov/16478755].
- Фарампатор. Выборка 16 человек в обеих группах в сумме [pubmed.ncbi.nlm.nih.gov/17119538].
Мелатонин. Выборка 50 человек в обеих группах в сумме [pubmed.ncbi.nlm.nih.gov/18853147]. - Толкапон. Выборка 34 человек в обеих группах в сумме [pubmed.ncbi.nlm.nih.gov/17063156].
- И так далее
Такие маленькие размеры выборки не позволяют выявить эффективен ли препарат. А показанные в таких экспериментах эффект, с большой вероятностью может быть случайным.
Может ли эксперимент показать эффективность добавок магния в капсулах для лечения чего угодно, если в нем участвуют 20 человек? Иными словами, если выборка 20 человек.
Давайте немного уйдем в сторону и рассмотрим пример. Можно ли будет сделать вывод, бросив монетку всего 20 раз, что чаще всего выпадает либо орел, либо решка? Читатель, вероятно, подумает, что орел или решка должны выпадать одинаково часто (50 на 50%). Остальное зависит от случайности.
 Рисунок 1. Если мы бросим монетку 20 раз, то по формуле Бернулли вероятность того, что орел и решка выпадут 50 на 50% = 0,176197052.
Рисунок 1. Если мы бросим монетку 20 раз, то по формуле Бернулли вероятность того, что орел и решка выпадут 50 на 50% = 0,176197052.
Таким образом, бросая монетку всего 20 раз, мы чаще всего увидим, что либо орел, либо решка выпадают чаще. И можем на основании всего лишь 20 бросков сделать ложный вывод, что орел выпадет чаще, либо что решка выпадает чаще. А вот если бы мы бросали не 20 раз, а все больше и больше, то результат был бы все ближе и ближе к равному количеству выпадений орла или решки (50 на 50%). Вот почему важно бросать монетку достаточно много. Вот почему в эксперименте с упомянутым выше магнием, должно участвовать достаточное для правильного вывода количество участников. И остается только определиться с тем, сколько нужно участников. Идем дальше.
Допустим, что мы хотим увидеть эффективность снижения высокого систолического артериального давления (САД) с помощью добавок магния в капсулах. Тогда мы выбираем две группы участников: пациентам из одной группы будем ежедневно давать капсулы с порошком из магния, а пациентам из другой группы (группа "плацебо") будем ежедневно давать капсулы с порошком из мела (плацебо, или иными словами - пустышку). Через 3 месяца такого лечения всем пациентам, участвующим в эксперименте, повторно измерим уровень САД. Среднее значение САД в каждой группе будем использовать для ответа на вопрос, было ли значимое снижение уровня САД в результате лечения магнием в сравнении с группой "плацебо", которая пила капсулы с мелом. Следующая формула подходит для определения размера выборки клинического исследования эффективности лекарственных средств, если в результате эксперимента необходимо измерить количественные данные (рост, вес, уровень артериального давления). Она не подходит для качественных данных (хорошо/плохо и т.п.).
Перед тем, как рассмотреть метод расчета размера выборки для эксперимента, поговорим немного о статистике.
Статистическая значимость – это параметр, который подтверждает, что результаты исследования были достигнуты не случайно. Понятие «статистическая значимость» в 1925 году ввел британский статистик сэр Рональд Фишер, который работал над методикой проверки гипотез.
Как правило, уровень значимости (обозначается, как p) в медицинских экспериментах устанавливается равной 0,05 и означает в нашем случае, что вероятность случайного обнаружения различий в уровне САД между группами ("магний" и "плацебо") составляет всего 5%. Если в результате эксперимента p окажется ниже, чем 0.05, значит результат окажется еще более значимым. Если в результате эксперимента p окажется выше, чем 0.05, значит результат окажется статистически не значимым.
Если мы хотим повысить достоверность наших данных, то можем установить значение p ниже 0,01. Но в этот раз мы этого делать не будем, а оставим p = 0,05.
Мощность исследования - это вероятность, с который между группой лечения магнием и группой плацебо в уровне САД будет обнаружена разница, при условии, что эта разница имеет место. При планировании исследования желаемая мощность обычно принимается равной 0,8 или 0,9.
Стандартное отклонение - это показатель того, насколько разбросаны результаты различных измерений (в нашем случае САД) по отношению к его среднему значению.
 Например, среднее систолическое артериальное давление (САД) = 120 мм ртутного столба, минимальное - 100, а максимальное - 140. Разброс значений систолического артериального давления от среднего будет +- 20 мм ртутного столба. Чем больше такой разброс, тем больше стандартное отклонение.
Например, среднее систолическое артериальное давление (САД) = 120 мм ртутного столба, минимальное - 100, а максимальное - 140. Разброс значений систолического артериального давления от среднего будет +- 20 мм ртутного столба. Чем больше такой разброс, тем больше стандартное отклонение.
Рисунок 2. Расчет стандартного отклонения для 5 пациентов.
Если мы не проводили собственное предварительное исследование, то данные для расчета стандартного отклонения можно взять из экспериментов других исследователей. Пример вычисления стандартного отклонения приведен на рисунке 2.
 Рисунок 3. Допустим, мы выбрали уровень статистической значимости 5% (p = 0.05), а мощность исследования 80% (0,8). Тогда формула расчета размера выборки для нашего эксперимента будет выглядеть следующим образом.
Рисунок 3. Допустим, мы выбрали уровень статистической значимости 5% (p = 0.05), а мощность исследования 80% (0,8). Тогда формула расчета размера выборки для нашего эксперимента будет выглядеть следующим образом.
Предположим, что стандартное отклонение (SD), обнаруженное в ранее проведенных исследованиях, составляло 18.5 мм ртутного столба (см. рисунок 2). Предположим, что величина эффекта (d) составит 5 мм ртутного столба (предполагаем, что магний снизит уровень САД на 5 мм ртутного столба). Тогда формула расчета размера выборки для нашего эксперимента будет выглядеть, как на рисунке 4.
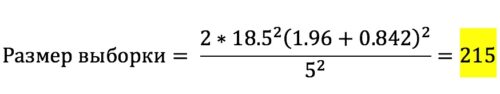 Рисунок 4.
Рисунок 4.
Таким образом, для нашего эксперимента необходимый размер выборки составит 215 человек для каждой группы. 215 человек для группы лечения магнием и столько же для группы "плацебо". А в сумме 430 человек для всего эксперимента. И теперь сравните цифру 430 и выборки по 20-40 человек из примеров, приведенных выше.
Данный расчет построен на основании исследовательской работы Джейкарана Чарана и Тамогна Бисваса [pubmed.ncbi.nlm.nih.gov/24049221].
Итак, достаточно ли для нашего эксперимента 20 участников, чтобы получить доказательство эффективности магния для снижения уровня САД, либо показанный с участием 20 человек эффект с большой вероятностью может оказаться случайным?
Для самых ленивых. Если Вам лень считать выборку, то просто примите тот факт, что редко какие исследования с выборкой менее 100 человек в группе, а в сумме 200 человек во всем эксперименте, могут показать статистически значимый результат. Относитесь скептически к экспериментам с выборками по 20-40 человек. Теоретические такие маленькие выборки могут предоставлять доказательства. Но только в том случае, если сила наблюдаемого эффекта в эксперименте очень большая. Например, если бы магний снизил артериальное давление не на 5 мм. рт. ст., а на 60-80 мм. рт. ст. в среднем для всех участников эксперимента. Но такое встречается очень редко. Даже лучшие назначаемые врачами лекарства от артериального давления в среднем в группе пациентов снижают давление на 10-15 мм. рт.ст.
Данный расчет, который я описал в статье, построен на основании исследовательской работы Джейкарана Чарана и Тамогна Бисваса [pubmed.ncbi.nlm.nih.gov/24049221]. Авторы этого исследования отмечают, что важно понимать, что метод расчета размера выборки различен для разных дизайнов исследований, и одна общая формула для расчета размера выборки не может использоваться для всех дизайнов исследований.
В этой статье я описал лишь упрощенную формулу для простого эксперимента в клинического исследования лекарства. Для более профессиональных расчетов выборки рекомендую изучить эти статьи [pubmed.ncbi.nlm.nih.gov/33958957] [pubmed.ncbi.nlm.nih.gov/33956359]. Особенно вот эту [pubmed.ncbi.nlm.nih.gov/32658647], которая подробно раскрывает методику и даже дает свой калькулятор [http://riskcalc.org:3838/samplesize/].
Знаете ли вы, что сайт nestarenie.ru — объективно один из самых популярных в России ресурсов про старение и долголетие - в Яндексе, в Гугле, по количеству, качеству и лояльности аудитории. nestarenie.ru имеет потенциал, чтобы стать одним из самых популярных сайтов о борьбе со старением не только в России, но и в мире. Для этого нужны деньги. Я призываю всех сделать пожертвования, а также убедить своих друзей поступить аналогично. Карта МИР в Сбере (рубли): 2202 2032 1501 6686 (МАЙЯВИ Ч.)
Обязательно оставляйте свои комментарии под статьей, которую Вы читаете. Это очень важно для нас.
Предлагаем Вам оформить почтовую подписку на самые новые и актуальные новости, которые появляются в науке, а также новости нашей научно-просветительской группы, чтобы ничего не упустить. Обязательно оставляйте свои комментарии под статьей, которую вычитаете. Это очень важно для нас.

Автор статьи
Веремеенко Дмитрий Евгеньевич
Телефон:
Почта:
Сфера деятельности - data science в медицине
Основатель проекта, изучающего терапии, направленные на увеличение продолжительности жизни человека (nestarenie.ru/slb-expert_.html)
Со-основатель IT сервиса продления жизни
Основатель форума о продлении жизни Nestarenie Camp (nestarenie.ru/camp.html)
Со-автор книги "Бонусные годы" (nestarenie.ru/kniga-3.html)
Создатель справочного блога о старении человека (nestarenie.ru)
Социальные сети:
- Карта Viza (доллары): 4215 8901 1587 0138 для переводов за пределами РФ
- Карта МИР в Сбере (рубли): 2202 2032 1501 6686 (МАЙЯВИ Ч.) - на территории РФ
16 комментариев
-
Sergey06 декабря 2022, 08:06
Стандартное отклонение и коэффициент 1.96 ( p-val = 0.05) используются только если данные подчиняются нормальному распределению.
Прежде чем применять формулу, нужно изучить то как распределены данные, часто никакого нормального распределения и в помине нет и расчет будет неверным.
Обычно ученые в разделе Statistical analysis описывают как показатели как распределены и если данные распределены нормально – то подают их в формате среднего ± стандарного отклонения. Если нормального распределения нет (что бывает часто), данные подаются в виде медианы и процентилей (это сразу знак что формула через 1.96 и SD не подходит).-
Дмитрий Веремеенко06 декабря 2022, 12:02
Рекомендует только врач. Я не врач, но делюсь данными исследований.
Отрезайте у ссылок http:Верно
-
-
Сергей23 ноября 2022, 18:07
Дмитрий, а вы не встречали в литературе использование не рандомного деление на тест / контроль (Т/К), а так, чтобы “выровнять” группы по составу, т.е. чтобы распределение показателей (пол, возраст, вредн. привычки, АД и т.д.) были максимально похожи между выборками? Можно ли в таком случае ограничиться меньшими выборками, если Т / К намеренно сделаны схожими? Это ,конечно, не отменяет “двойного ослепления” эксперимента.
-
Дмитрий Веремеенко23 ноября 2022, 18:29
Рекомендует только врач. Я не врач, но делюсь данными исследований.
Отрезайте у ссылок http:Встречал.
-
Сергей26 ноября 2022, 11:02
Дмитрий, а если использовать не рандомное деление на тест / контроль (Т/К), а «выравнивать» группы по распределению показателей (пол, возраст, вредн. привычки, АД и т.д.) , то какой наименьшей размер выборки допустим?
-
Дмитрий Веремеенко26 ноября 2022, 21:49
Рекомендует только врач. Я не врач, но делюсь данными исследований.
Отрезайте у ссылок http:огромный. Так как в таком случае РКИ превращается в обычное наблюдательное. Так как деление не рандомное – не лишено субьективности
-
Сергей27 ноября 2022, 10:30
ясно, рандом рулит ) Осталось понять, а нельзя ли и тут добавить “субъектности”, т.е. можно ли им “управлять”? как проверяют / подтверждают рандомность деления? Есть ли в протоколах формула рандомности? – типа: дата начала+фио пациента+пол+возраст+паспортные данны в хеш функцию + сложное ключевое слово -> воспроизводимо получаем 1 / 2. Проверяете. А то так “рандомно” можно насыпать хиляков в контроль и здоровяков в тест и доказать пользу курения к примеру.
-
Дмитрий Веремеенко27 ноября 2022, 20:38
Рекомендует только врач. Я не врач, но делюсь данными исследований.
Отрезайте у ссылок http:Рандомизация как раз и делает то, что уравновешивает группы по параметрам. Только делает это ни как человек по своему усмотрению, а случайно.
-
Сергей28 ноября 2022, 19:30
вы – “Рандомизация как раз и делает то, что уравновешивает группы по параметрам”.
А я спросил – кто проверяет эту “рандомность”? Есть ли независимая проверка кем угодно, кто хочет сам удостовериться? Ведь легко обмануть/запутать исследование, если рандомность нельзя независимо проверить. В идеале каждый может проверить, что да – деление было рандомно. Если же деление делалось “рандомно” никому не доступным черным ящиком, “отвественным комитетом специальных математиков”, то это прямой путь к махинациям. Т.е. поверьте нам на слово, деление было рандомно, а не “рандомно”. Я думаю, вы меня поняли и уклоняетесь от прямого ответа, потому что тема скользкая и закрытая. Верьте нам, там все честно, зуб даем, у нас нет там интереса – как я понял, вот основные киты, на которых сейчас держатся РКИ. -
Дмитрий Веремеенко28 ноября 2022, 21:35
Рекомендует только врач. Я не врач, но делюсь данными исследований.
Отрезайте у ссылок http:Проверить можно, но уже после окончания эксперимента. Так как в идеале до окончания эксперимента все его участники должны быть ослеплены. И уже когда экперимент закончился, можно посмотреть, как была выполнена рандомизация. Поэтому это проверяемая часть. Более того – это обязательно потом проверяют в правильном эксперименте
-
Сергей29 ноября 2022, 09:52
вы – “И уже когда экперимент закончился, можно посмотреть, как была выполнена рандомизация. Поэтому это проверяемая часть. ”
Про “ослепление” и “когда закончился” это трюизмы, можно было и опустить.
Вы как независимый исследователь сможете сами проверить? Взять списки участников, врачебные протоколы наблюдения и самому посчитать эффект, пользуясь предоставленным после эксперимента “рандомизатором” – посмотрите выше, я писал “в хеш функцию передавать: дата начала+фио пациента+пол+возраст+паспортные данные + сложное ключевое слово”. “Ключевое слово” – это “секрет”, “пароль” публикуемый после завершения эксперимента. Ну или что-то подобное, доступное каждому.
Или вы полагаетесь на честно слово “дядечек”, которые все “честно поделили”?
Или к примеру: вот вам списки участников, хотите ищите сами, где мы тут нахимичили. -
Дмитрий Веремеенко30 ноября 2022, 22:38
Рекомендует только врач. Я не врач, но делюсь данными исследований.
Отрезайте у ссылок http:Да. Могу. Берём первичные данные, которые публикуются обязательно сразу после рандомизации и запрашиваем у исследователей уточнения по этим первичным данным. Они как правило без проблем это предоставляют. Я проверял некоторые исследования таким образом.
-
Сергей03 декабря 2022, 11:24
Вы: “Да. Могу. Берём первичные данные, которые публикуются обязательно сразу после рандомизации и запрашиваем у исследователей уточнения по этим первичным данным.”
Понятно, это похоже на то, что я выше написал:
“вот вам списки участников, хотите ищите сами, где мы тут нахимичили.”И ведь не найдете, так как небольшой перекос в группах “то тут, то там” всегда можно списать на случайность деления, а эти то тут / то там могут проявиться в плюсовании результата теста или минусовании контроля. Это как искать иголку в стоге сена – тот, кто ее подложил, знает где она и что она такое, а любой другой потратит годы на анализ / поиск подложенной иголки (свиньи).
Я же спрашивал, контролируется ли сам рандомизитатор, т.е. его “неслучайная” случайность? Тогда и “первичные данные” проверять не надо в поисках подложенной свиньи, так как “рандом рулит”.
Единственно, для защиты от махинаций с рандомизатором нужна независимая “группа рецензентов/критиков”, которые предоставят свою часть секретного ключа (секретн. ключ исследователей+ ключ “критиков” + независим. от всех них организация, которая владеет рандомизатором тоже давать свой ключ – типа: “номер исследования + дата деления”).
Это нужно, чтобы не было попыток перебором ключевых слов подобрать случайное деление, которое случайно получилось особо удачным для тестовой группы.
-
-
-
-
-
Viktar22 ноября 2022, 20:43
Отличная статья! Теперь количественно понятно, какая выборка является достаточной
-
Карим22 ноября 2022, 20:31
Благодарен за статью. Появился вопрос, на каком основании построены эти формулы ? Почитал статью, что-то не нашёл. На основе успешного применения определенного ряда результатов исследований ?
-
Дмитрий Веремеенко22 ноября 2022, 21:07
Рекомендует только врач. Я не врач, но делюсь данными исследований.
Отрезайте у ссылок http:Данный расчет, который я описал в статье, построен на основании исследовательской работы Джейкарана Чарана и Тамогна Бисваса [pubmed.ncbi.nlm.nih.gov/24049221]. Авторы этого исследования отмечают, что важно понимать, что метод расчета размера выборки различен для разных дизайнов исследований, и одна общая формула для расчета размера выборки не может использоваться для всех дизайнов исследований.
——
В этой статье я описал лишь упрощенную формулу для простого эксперимента в клинического исследования лекарства.Для более профессиональных рассчетов выборки я скоро рассмотрю содержание вот этих статей
pubmed.ncbi.nlm.nih.gov/33958957
pubmed.ncbi.nlm.nih.gov/33956359Особенно вот этой [pubmed.ncbi.nlm.nih.gov/32658647], которая подробно раскрывает методику и даже дает свой калькулятор [http://riskcalc.org:3838/samplesize/]
-
Свежие комментарии
Подпишитесь на свежие статьи
Предлагаем Вам оформить почтовую подписку на самые новые и актуальные новости, которые появляются в науке, а также новости нашей научно-просветительской группы, чтобы ничего не упустить.